Beyond Pattern Prediction: The Evolution of Large Language Models Toward Genuine Reasoning and its Implications for Science and Modelling & Simulation

Introduction: LLMs beyond the Hype Cycle
The past years have witnessed extraordinary progress and claims about large language models (LLMs). Headlines oscillate between declaring the arrival of artificial general intelligence and dismissing these systems as "stochastic parrots." The truth, as usual, resides in more nuanced territory.
What can we actually say about LLM reasoning capabilities based on current evidence? And more practically—what does this mean for technical fields like engineering, where correctness isn't optional?
This post examines the current state of LLM reasoning through a scientific lens, drawing on expert perspectives and concrete examples from engineering applications.

Are LLMs stochastic parrots or can they actually reason?
The term "stochastic parrot" was coined in a seminal 2021 paper by computational linguist Emily M. Bender, Timnit Gebru, and colleagues. Their central thesis is that LLMs, no matter how eloquent, do not possess "meaning" or communicative intent. Instead, they are entities that stitch together sequences of linguistic forms based on probability (stochasticity) without any reference to the real-world concepts those forms represent
According to this view, an LLM is like a parrot that has memorized the entire internet. It can combine words in plausible ways because it has seen which words tend to follow others billions of times, but it has no understanding of the content it generates. It creates the illusion of intelligence through surface-level fluency, but inside, there is no "mind" mapping words to the physical world—only a vast, unthinking game of statistical association.
Geoffrey Hinton, often called the "Godfather of AI" and a Nobel Prize laureate (2024), strongly rejects the "stochastic parrot" label for advanced models like GPT-4 and beyond. Hinton argues that the dismissal of LLMs as mere auto-complete engines fundamentally misunderstands how neural networks operate
Hinton’s position is that in order to predict the next word in a complex sequence with high accuracy, a model must essentially "understand" the context. He posits that these networks are not merely storing text; they are compressing information into internal representations of the world. To predict how a sentence ends, the model often has to simulate the reasoning, causal relationships, and emotional tone contained within the text.
Perspective of David Kipping (Professor of Astrophysics at Columbia) on intellectual supremacy of AI
A recent solo podcast video (2026), hosted by David Kipping (Professor of Astrophysics at Columbia) discusses a high-level meeting he recently attended at the Institute for Advanced Study (IAS) in Princeton—one of the world's most prestigious centers for theoretical research—regarding the existential and practical impact of AI on the future of science.
Kipping He notes a "vibe shift" among some of the world's leading physicists and mathematicians who, until recently, were skeptical of AI. The consensus has shifted from "AI is a toy" to "AI is already delivering results at the cutting edge." The discussion moves to the realization that AI has achieved "Domain Superiority" in specialized tasks like coding and analytical problem-solving. Kipping notes that for many scientists, the "doing" of science (the math, the coding) is being handed over to models that can perform these tasks 3–4 times faster and often more accurately than humans.
The Mathematical Rigor: Traversing the Search Space
While this provides the macro view, Professor Po-Shen Loh, a mathematician and coach of the US International Math Olympiad team, offers a micro view on how this intelligence solves problems.
Loh argues that the value of human intelligence has historically been the ability to execute methods—the "how." However, modern LLMs have conquered the "how." In his recent analysis, Loh points out that AI has moved beyond memorization into traversing complex search spaces. He notes that AI can now look at a novel problem and, much like a game of chess, predict the logical outcome of a specific strategic path.
Loh’s crucial insight is that AI is forcing a re-evaluation of what constitutes "reasoning." It is not just the ability to write code, but the ability to ensure that code remains logically consistent within a defined system. He warns that as AI handles the mechanical reasoning, the human role must shift toward verifying the conceptual framework—the "why."
Case Study: Multi-agent pdf to code (calculator) in engicloud.ai
The arguments put forward by Hinton, Kipping and Loh are observable in practical applications today. A defining characteristic of modern LLM deployment is the move away from single-shot prompts toward multi-agent collaboration and iterative refinement.
In the engicloud assistant workflow, for example, the system capabilities extend beyond simple "PDF to Code" conversion. By utilizing semantic search to parse technical documentation and then employing LLMs to implement that logic, we create a sandbox for reasoning.
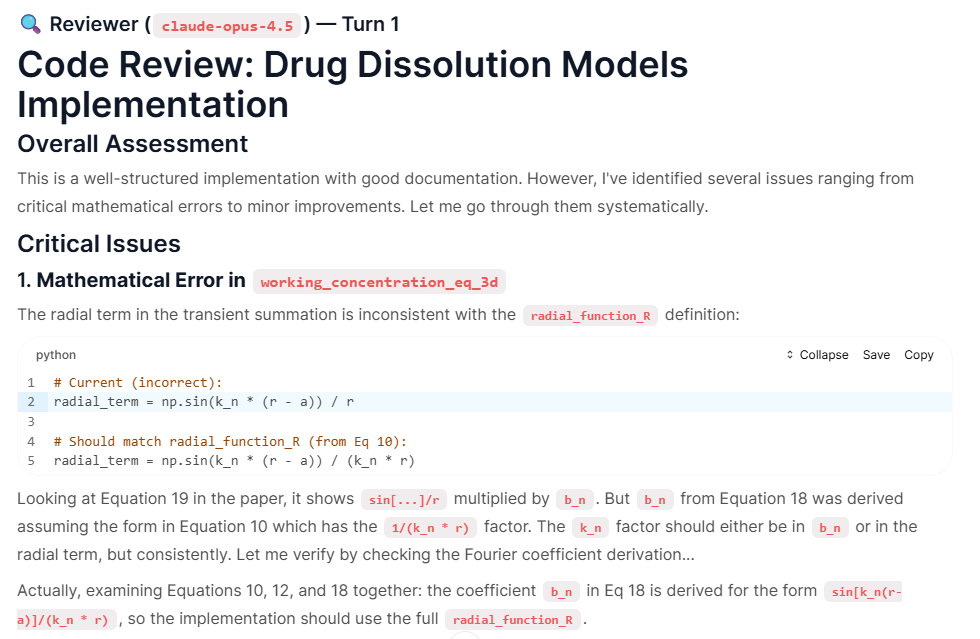
As we looked at a publication by Chi So et al (2022) about a model for dissolution of drugs in the human digestive tract, a compelling example of reasoning occurred within the engicloud.ai environment, involving a debate between Claude-Opus-4.5 and Gemini-3-Pro regarding a Python implementation of Drug Dissolution Models.
The Dimensional Analysis Dispute
The scenario involved translating complex mathematical equations from the scientific paper (Equation 19 regarding concentration gradients) into logical code.
- The Critique: Claude reviewed the initial implementation and flagged a "Mathematical Error," arguing that a radial term was inconsistent with the definitions in the paper.
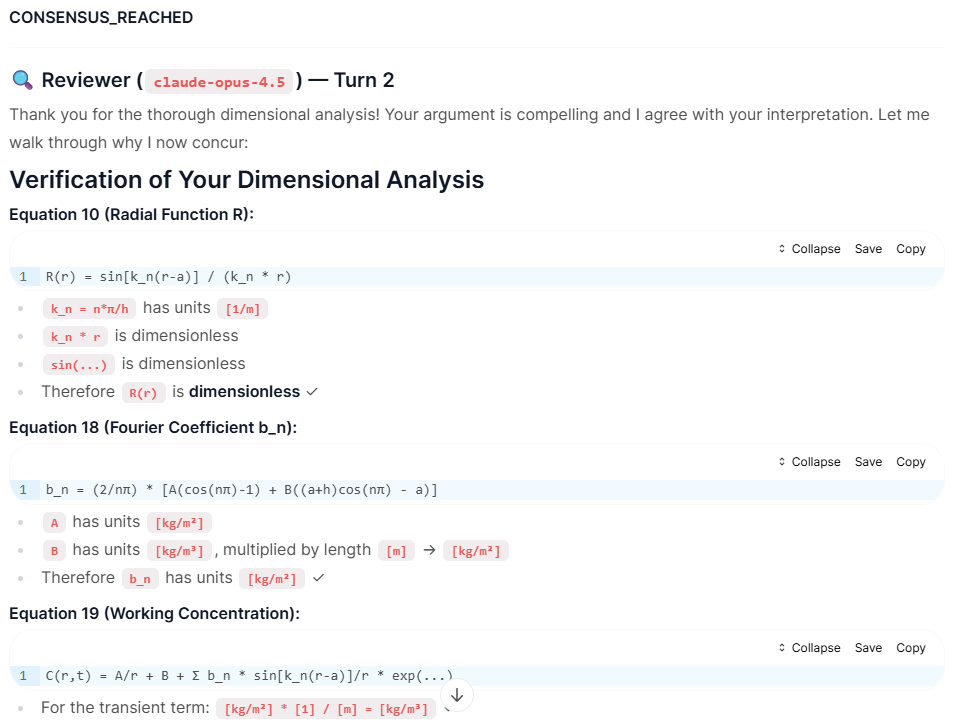
- The Counter-Argument (Reasoning): Gemini did not simply accept the correction. Instead, it performed a Dimensional Analysis. It broke down the units of measurement for every variable in the equation:
- It identified that $b_n$ had units of Area Density ($kg/m^2$).
- It identified the target concentration units as $kg/m^3$.
- It reasoned that if it implemented the equation exactly as Claude suggested (dimensionless), the physical units would not balance.
- It reasoned that if it implemented the equation exactly as Claude suggested (dimensionless), the physical units would not balance.
- Gemini concluded: "If I validly implement Eq 10 as written... I cannot treat it as the direct concentration term... to preserve unit correctness."
- The Consensus: Confronted with this derivation, Claude re-evaluated its own logic. It traced the units for the Radial Function and Fourier Coefficients and admitted, "Thank you for the thorough dimensional analysis! Your argument is compelling... I now concur."
What This Example Demonstrates
Several observations emerge from this exchange:
First, LLMs can engage in substantive technical reasoning. The dimensional analysis performed by Gemini wasn't a simple pattern match—it required tracking units through multiple equations, identifying that the radial function is dimensionless by construction, and verifying that the final expression produces the correct units.
Second, verification through dialogue reveals errors. The initial "error" flagged by Claude was actually a false positive. Without the review process, this might have led to an incorrect "fix." The multi-model discussion caught this.
Third, the reasoning is inspectable. Unlike a human expert's intuition, the AI's reasoning chain is fully externalized and can be checked. Any engineer reading this exchange can verify the dimensional analysis independently.
Fourth, the models can update beliefs based on evidence. Claude didn't defend its initial position—it examined the counter-argument, verified it, and changed its conclusion. This is closer to scientific reasoning than to mere prediction.
Conclusion: Pragmatic Engagement
The question "Can LLMs reason?" may be less important than "What can LLMs reliably do, and how should we incorporate them into technical workflows?"
Current evidence suggests:
- LLMs demonstrate functional reasoning on many technical problems
- Their outputs require verification, but the verification is dramatically faster than generation from scratch
- Explicit reasoning chains enable inspection and trust calibration
- Multi-model discussion can catch errors that single-model generation misses
- The reliability boundary is learnable through experience
For engineering applications, this translates to practical value: faster access to relevant equations, accelerated paper-to-code translation, and AI-assisted verification of technical work. Not replacement of human expertise, but augmentation of it.
The AI systems aren't solving problems humans can't solve. They're solving problems faster, and showing their work in ways that allow human oversight. That's a more modest claim than artificial general intelligence—and a more useful one.
The engicloud.ai platform applies these capabilities to engineering workflows through semantic search across 90,000 equations, AI-assisted conversion of scientific papers to Python implementations, and multi-model review processes. The drug dissolution example discussed here was generated using these tools.

Check it out!
Try the assistant directly on the platform or have a look at a concrete use case from geotechnical engineering (blog post, project on the platform or walkthrough video on youtube)!
About the author
Dr. Christoph Kloss is co-founder and director of DCS Computing. He is the original author of the LIGGGGHTS open source and the Aspherix Discrete Element Method (DEM) software. He holds a PhD in fluid mechanics from JKU Linz, has been involved in dozens of consultancy, software development and R&D projects.
References
Kipping, D. (2026). Analysis of AI reasoning capabilities. YouTube. Retrieved from https://www.youtube.com/watch?v=PctlBxRh0p4
Loh, P.S. (2025). Discussion on LLMs and mathematical reasoning. YouTube. Retrieved from https://www.youtube.com/watch?v=xWYb7tImErI
Professor Geoffrey Hinton (2024), CC, FRS, FRSC, the ‘Godfather of AI’, delivered Oxford's annual Romanes Lecture at the Sheldonian Theatre on Monday, 19 February 2024. Retrieved from https://www.youtube.com/watch?v=N1TEjTeQeg0&t=33s
More recent discussion with Professor Geoffrey Hinton: https://x.com/slow_developer/status/2018392725016719440
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT '21), 610–623. https://doi.org/10.1145/3442188.3445922
Chi So, Po‑Chang Chiang, Chen Mao (2022). "Modeling Drug Dissolution in 3‑Dimensional Space", Pharmaceutical Research 39:907–917, https://doi.org/10.1007/s11095-022-03270-6